Recurrent Neural Networks
AI Series - Chapter 23
I am a software engineer.
Hi 🦾,
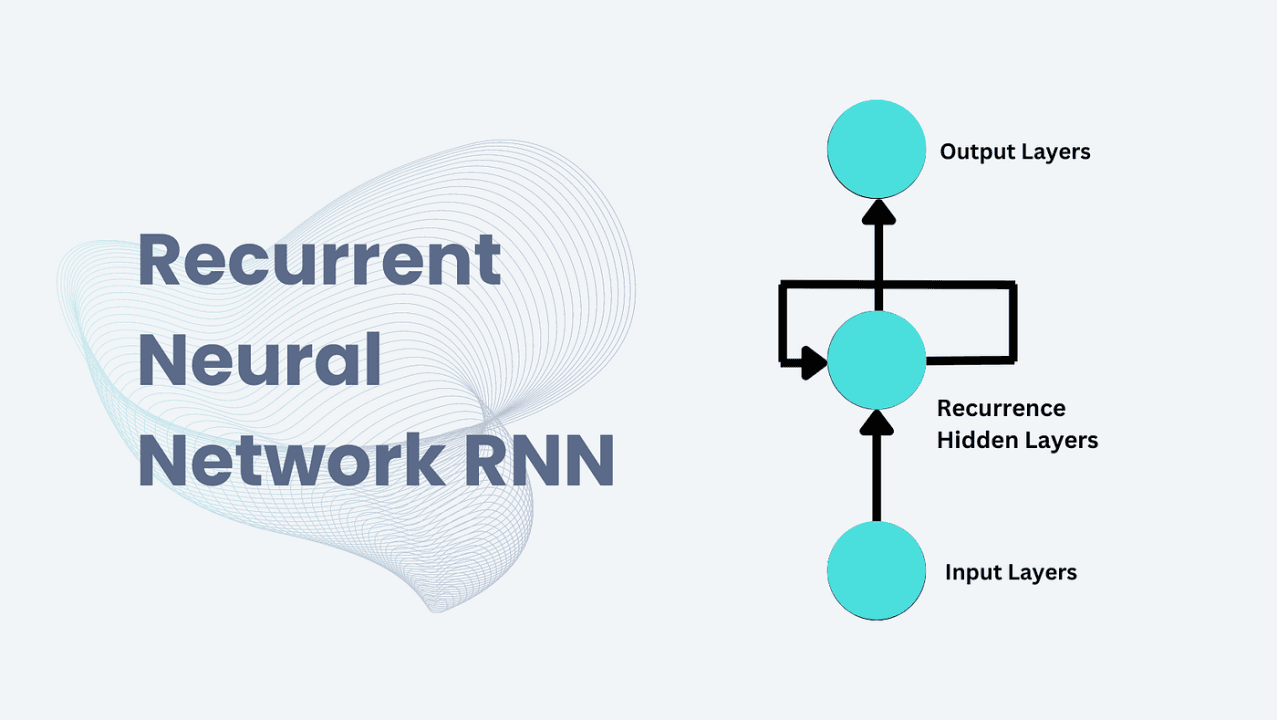
A Recurrent Neural Network (RNN) is a type of neural network designed for processing sequential data by maintaining a hidden state that serves as memory. Unlike traditional neural networks, RNNs have a feedback loop that allows information to persist across time steps, enabling them to capture dependencies in sequential data.
The image below illustrates the difference between RNNs and traditional neural networks like the Feedforward Neural Network. We can see that RNNs have a hidden “memory” layer in each node. Each of these memory layers keeps track of previous input so it can predict what the next output should be.

How RNNs work
Recurrent in RNN means a feedback loop. Each input is passed to a node on the neural network with the previous output continuously in a loop as shown in the image above. The structure of an RNN node consists of the input layer (Xt), the output layer (Yt), and the hidden state (Ht) as shown in the image above.
Training
Training an RNN model involves a few steps:
Prepare the data: If you remember how we did with our other models, we have input and output data like so:
Input (X): "I am feeling under the " Output (Y): "weather"If we remember the inputs are called feature vectors, you can brush up more on that in Chapter 3, where we discussed those terminologies in detail.Train the model: To train the model the key item here is how the hidden state(Ht) is updated:

If you have forgotten what bias, weights, and activation functions mean you can brush Chapter 20, Introduction to Neural Networks. This step is where the feedback loop comes in to update the hidden state at each iteration/step.
Inference
So now, when I pass a sentence, I’ll expect the model to be able to get the context and provide the appropriate next word as output.
To understand more in-depthly how RNNs work I’ll recommend a YouTube video here.
Types of RNN
There are different types of RNN models as shown below

For example, the Many-to-many type of RNN is used in stock price prediction, where a series of stock prices of the previous week, month, or year is passed as input, while the output would be the stock prices of the next week, month, or year respectively.
An example of the Many-to-one type of RNN can be seen in sentiment analysis, where a list of words possibly from a sentence is passed to the model as input, while the model gives an output of a number between 0 and 1, where 0 means bad sentiment and 1 good sentiment. Companies use Sentiment Analysis to evaluate their user feedback on products and services.
Applications of RNNs
RNNs are used in text prediction, weather forecasting, or stock price trends, where patterns are learned from past data.
For example, when you use your phone keyboard to type with auto-complete, the next-word suggestions are made with a similar technique. For example when you start typing something like:
I am feeling under the…
The RNN model would be able to predict that the next word might most probably be weather, so it’ll add weather in the next word suggestion thus it’ll be:
I am feeling under the weather.
To achieve that, the RNN has to try to remember all the previous words in the sentence to be able to predict the most probable next word, which leads to what is called the Long Term Dependency Problem in data with large sequences.
Limitations of RNNs
RNNs have some limitations when working with large datasets. Since they keep track of all previous inputs to predict the next output, they can easily lose context and meaning as the number of inputs increases. This is known as the Long-Term Dependency Problem, also known as the vanishing/exploding gradient problem.

To illustrate this, let’s say you’re telling a 3-year-old baby a bedtime story. That goes like so:
“Once upon a time, there was a brave knight who fought a dragon. The end.”
The baby understands and remembers every word of the story.
But now consider telling the story like so:
“Once upon a time, there was a brave knight who set out on a grand quest. After traveling through dark forests, crossing mighty rivers, and climbing high mountains, he finally reached..."
Now be prepared to be asked a lot of questions by the baby, because they can’t process all that information and remember every detail. Well, even you would not remember every word 😄. You know that’s why children’s books have more pictures and fewer words.
The illustration above explains what happens with regular RNNs. Since they try to keep track of every word to predict the next word, they can easily lose context as the text increases (I am using text as an example of data).
Because of the limitations of RNNs as explained above, there are two updated versions of RNNs that try to solve these problems:
Long Short-Time Memory (LSTM) Networks: These update RNN architecture using gates to control the flow of information and memory cells to save information for longer instead of the hidden state of the regular RNN. LSTM uses 3 gates, forget, input, and output gates respectively for managing the flow of information to the memory cell. In simple terms, the gates here try to keep only the important information, like a summary of each sentence or current context, so it is easier to keep track of the meaning of the previous inputs.
Gated Recurrent Units (GRUs): These are updated versions of the LSTMs. GRUs use 2 gates the reset and update gates respectively. With fewer gates, GRUs are faster than LSTMs in most tasks.
Keep in mind that the addition of gates and memory cells makes training LSTMs and GRUs slower and more expensive than regular RNNs. However, LSTMS and GRUs perform better than regular RNNs in most tasks requiring long sequences of text.
RNNs are not commonly used nowadays as the rise of Transformer Models beat the performance of RNNs. We’ll learn about Transformer models in our series very soon.
Don’t forget we’ll still build and deploy these models as we usually do.
This might be a lot to take in, so take your time and read in bits if you have to. Up next we’ll learn about Generative Adversarial Networks, the neural network that can generate new images for you from a prompt.