K-Nearest Neighbors - Supervised Learning Classification
AI Series - Chapter 5

I am a software engineer.
print("K-Nearest Neighbors")
K-Nearest Neighbors(KNN) is a supervised learning model used in classification and regression tasks. KNN makes predictions for an outcome based on its closest neighbors. For the course of this chapter, we'll be discussing KNN in classification.
The philosophy behind KNN in classification tasks is to classify an item based on the distance between it and its closest neighbors. The K in K-Nearest Neighbors stands for the number of neighbors used to make the prediction.
This works by counting the number of the neighbors closest to it of the same class and assigning the item to the class with the highest number of neighbors.
Consider the illustration below, containing houses plotted on a 2D plane based on the year the house was built and the house size.
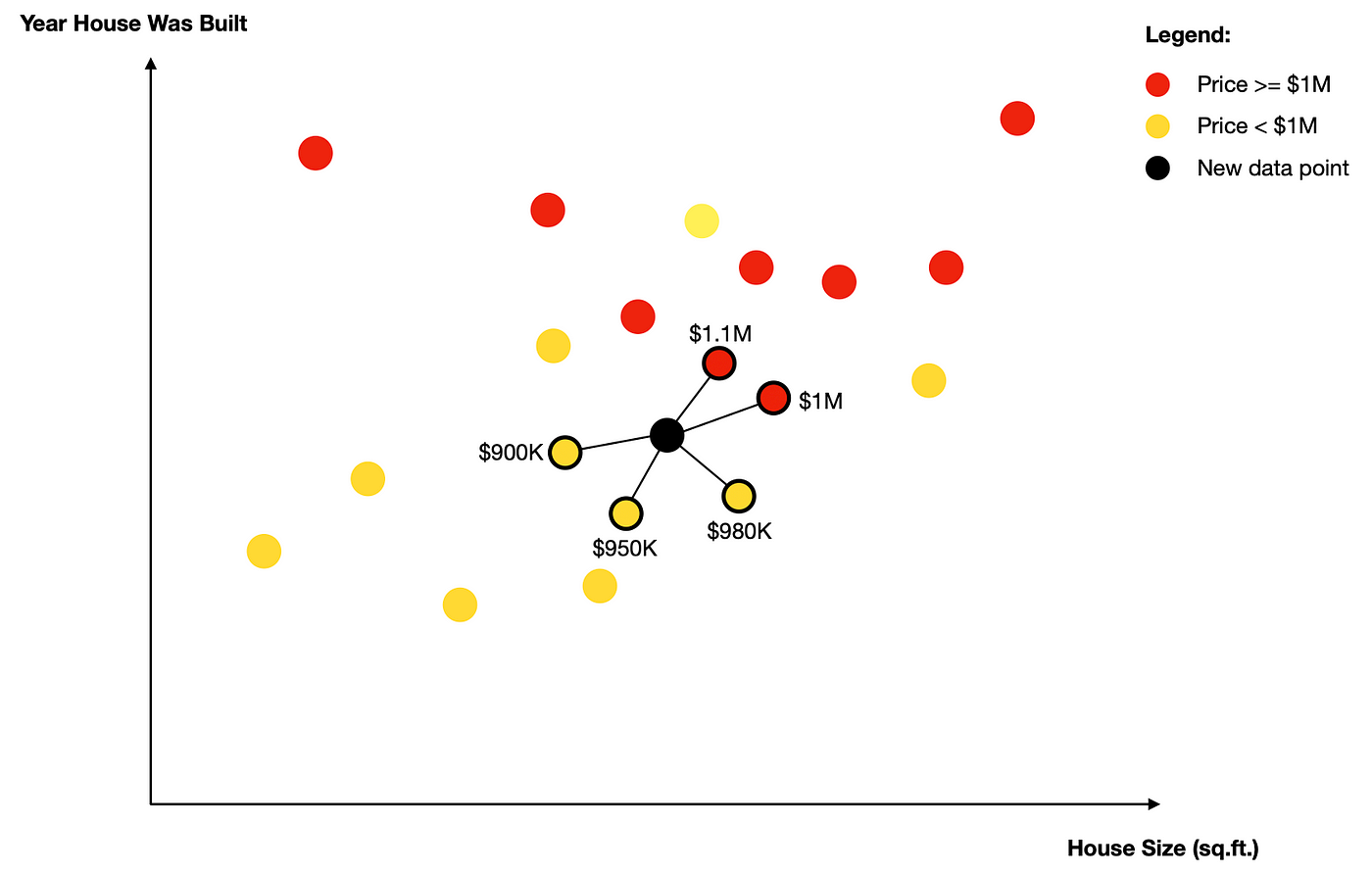
Say we want to predict the price of a new house(item with the black color). We first select the number of neighbors K, to use. In the illustration above we use K=5. So we get the closest 5 neighbors to the item. We get the closest neighbors by calculating the Euclidean distance, which simply means the straight line distance.
The formula for calculating Euclidean distance:
d = sqr((x1-x2)^2 + (y1-y2)^2)
This is calculating the distance from the y-axis and x-axis on the 2D plane.
After getting the 5 closest neighbors of our house, we'll count the neighbors. The neighbors of a particular class with the highest count win, that's the yellow-labeled houses in our case, with 3 out of 5. Therefore our model would predict that the house belongs to the yellow class. This means our KNN model would predict that the house is less than $1m 😊.
From our example, we can see that KNN does not "actually" learn rather it uses the training dataset to always try to calculate the neighbors for a new item.

KNN is called a lazy learning algorithm in Machine Learning because it uses the entire training dataset to make predictions. This can make it computationally expensive for large datasets. Because it'll have to store the dataset.
To go into a little more detail you can read more here.
I made a simple demo site for you to test each model we talk about, https://retzam-ai.vercel.app/.
For supervised learning classification I trained a model to determine the manufacturer of a car given some features using KNN.
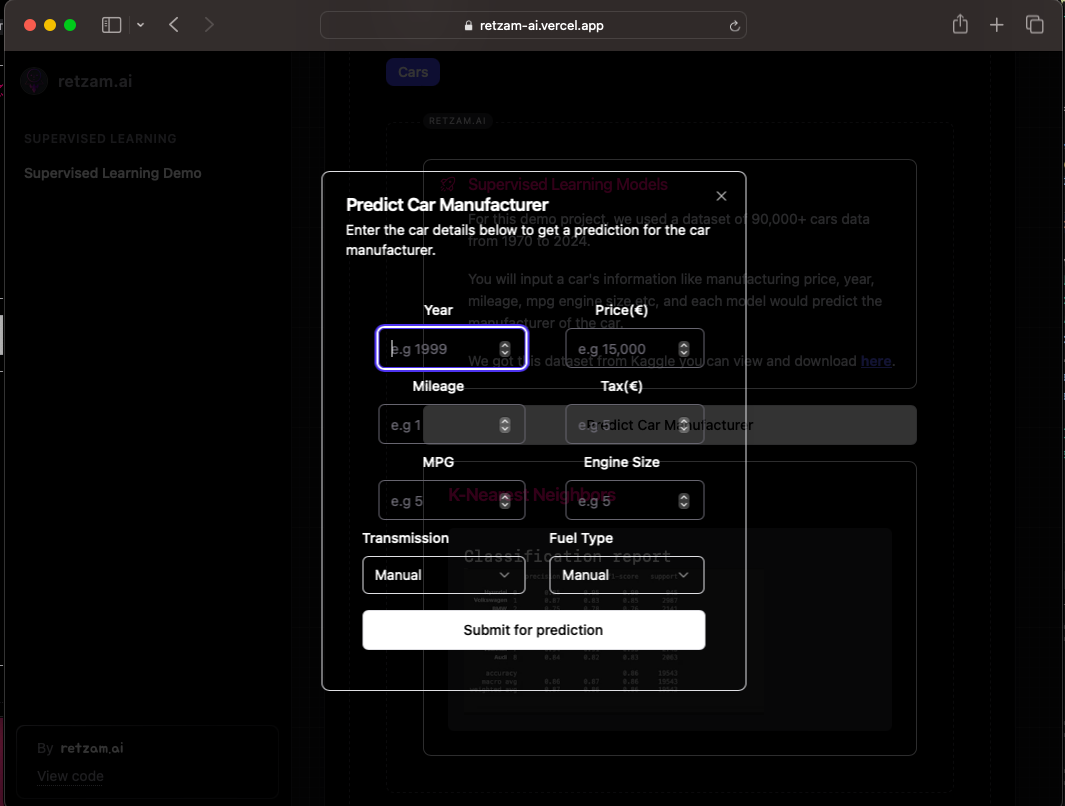
It'll be able to predict the manufacturer of the car.
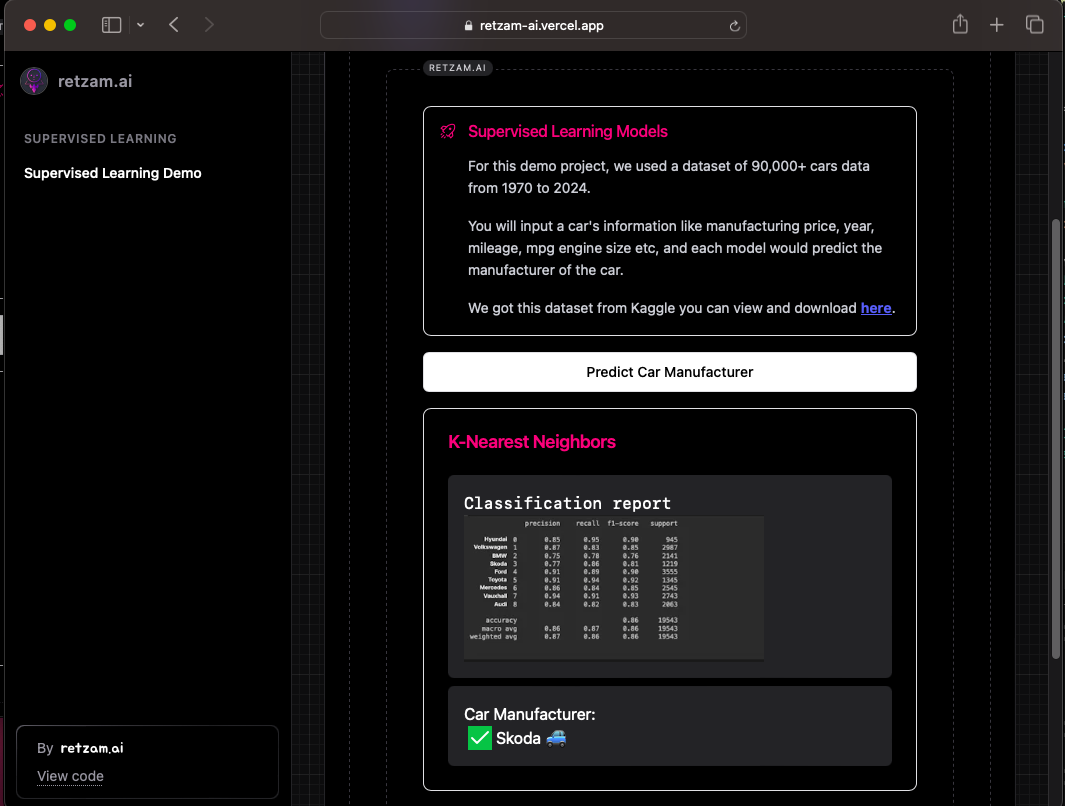
Visit the demo site and try the demo projects, it'll help you see how it works in real-life scenarios.
The rest of this chapter is optional for those who want to see how it is implemented hands-on. I recommend it for everyone though. If not you can skip to the end 🙂.
For each AI model chapter, we'll have a hands-on section where we'll train our own model.
We'll use Python for the hands-on section, so you'll need to have a little bit of Python programming experience. If you are not too familiar with Python, still try, the comments are very explicit and detailed.
We'll use Google Co-laboratory as our code editor, it is easy to use and requires zero setup.Hereis an article to get started.
Hands-On
Here is a link to our organization on GitHub, https://github.com/retzam-ai. Please feel free to fork any project you are interested in, make updates as you deem fit, and send in a Pull Request. If your Pull Request is merged, you'll be added as a contributor to the project. It doesn't matter if your PR only fixes a typo, so give it a go 🙃!
For this demo project, we'll use a dataset of 90,000+ Cars Data From 1970 to 2024 from Kaggle, you can check it here. Our aim for this project is to be able to predict the manufacturer of a vehicle. We'll use the K-Nearest Neighbours model for this project.
So let's start 👽🎮
For the complete code for this tutorial check this pdf here.
Data Preprocessing
First, go to your Colab page and create a new notebook.
Go to Kaggle here, to download the cars dataset.
Click on the folder icon by your left and drag and drop the CarsData.csv file you've downloaded.
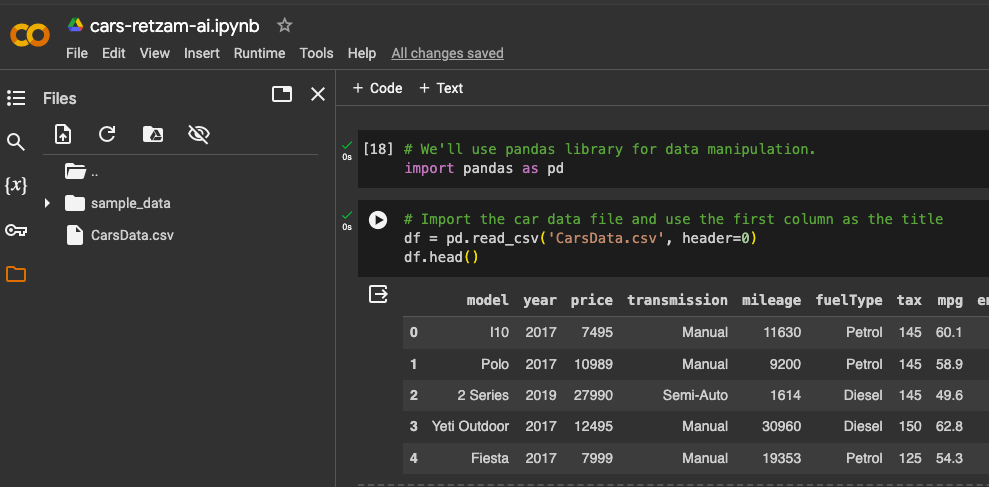
Import pandas which is the library we'll use for data manipulation. Now import the car data and use
df.head()to show the first 5 table rows, as shown in the image above.Now if you observe we have columns with text like model and transmission. These are nominal data if you remember we talked about that. We'll need to convert this to numbers so our model understands this better.
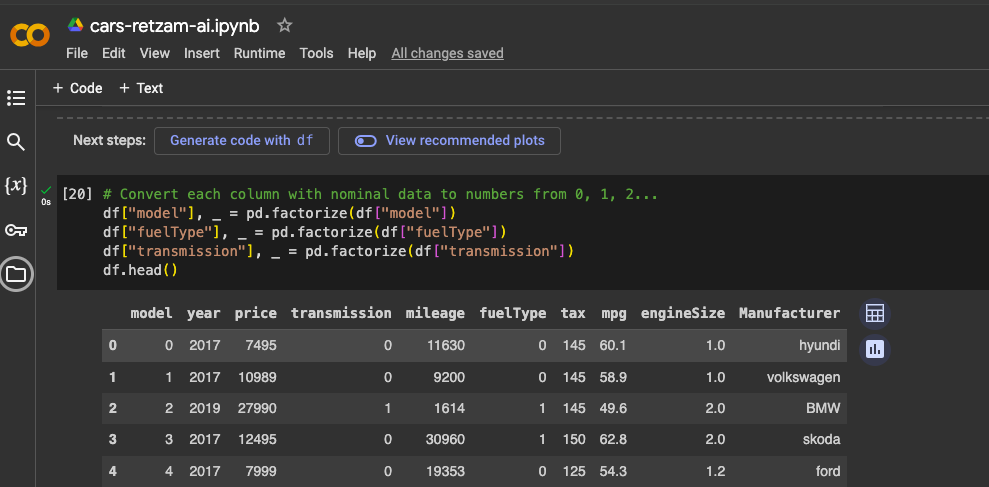
Now our dataset is looking good.
Up next, we'll need to split our dataset into training and test datasets. We are omitting the validation dataset because it is not required for KNN classifiers. We'll split them in 80%-20% for training-test datasets.
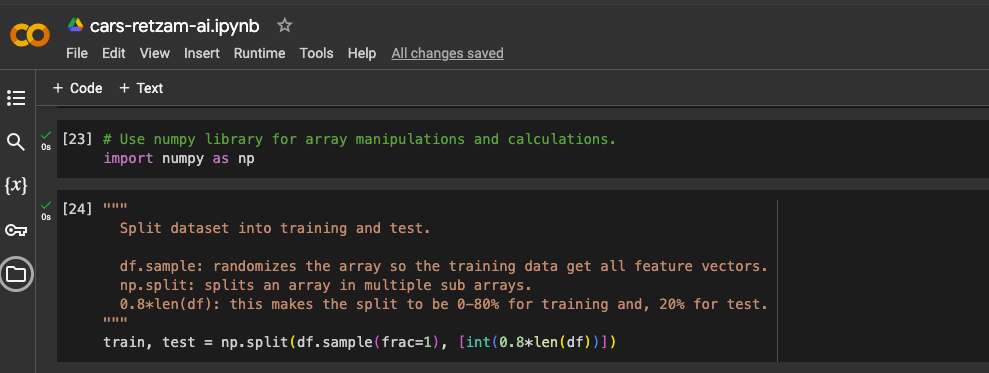
Finally, we'll scale our feature vectors to help us remove outliers and to over-sample when required. The pdf code file has explicit comments explaining this.

Train model
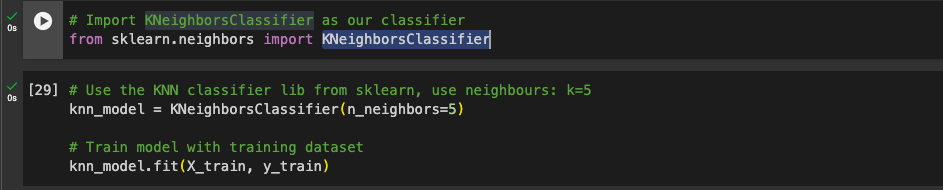
We don't need to create our KNN classifier from the bottom up by ourselves we'll use a library that already implements it from Scikit-learn: KNeighborsClassifier. So we'll import it and train our model with our training dataset. We used k=5, which means 5 neighbors.
Performance Review
First, we'll need to make predictions with our newly trained model using our test dataset.
Then we'll use the prediction to compare with the actual output/target on the test dataset to measure the performance of our model.
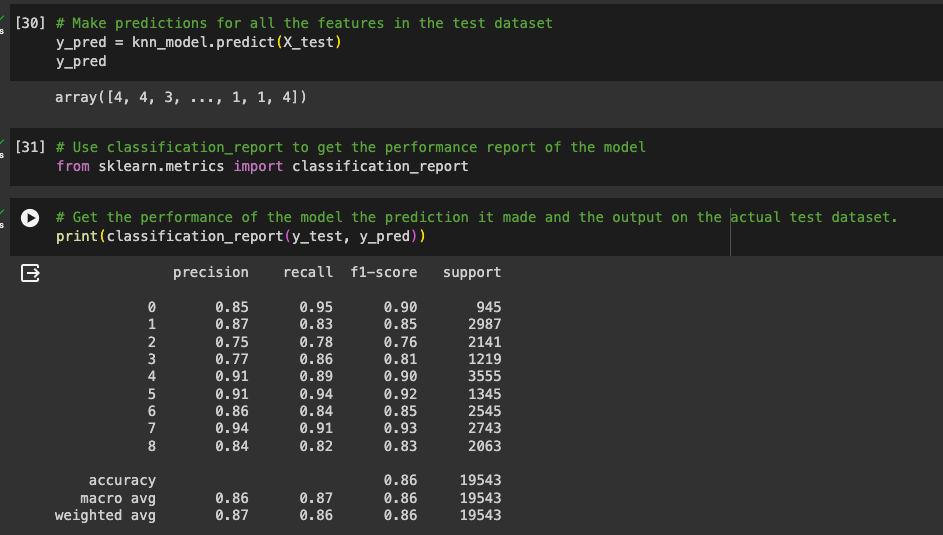
We can see precision and recall at the head of the table. I am sure we remember what they mean right lol. So for each output from 0-8, we have a precision and recall value. This is measured from 0 - 1.
The F1 Score is a combination of precision and recall. Our scores for each are quite good, right?
Also, we can see the accuracy as 0.86 which is quite good.
Our model performance is good, not perfect but the 86th percentile is very good 👽. This means our model has 86% accuracy in making the correct prediction.
From this, you can predict a car's tax, price range, and so on. Check out the codebase and try to train a model to predict a different output based on this dataset. Like a car's tax range or price range.
End of hands-on
😁 for those who tried the hands-on what do you think? let me know, please. Also remember it's all about practice 🎮.
For those that skipped it's all good 😶.
Our next chapter would be even more interesting: Naive Bayes. Stay tuned we are just getting started 👽!