I am a software engineer.
Hello 👽,
I was telling you the story of the Google Brain and Research teams, right? Yes, so let’s continue. If you are just joining, you might need to read our previous chapter, Introduction to Transformers 1. Also, you can access their paper, Attention Is All You Need, here.
Where did we stop again? Yes, where they decided to build a transduction model without an underlying RNN or CNN, with only an attention mechanism. Now, the Ladies and Gents of the Google teams, after much research, said to themselves; You know there’s this Attention mechanism called self-attention, right? It might just be the right fit for this project.
To proceed, let’s learn about self-attention.
Self Attention
Self-attention, also known as intra-attention, is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. How does it work?
Consider the illustration below.
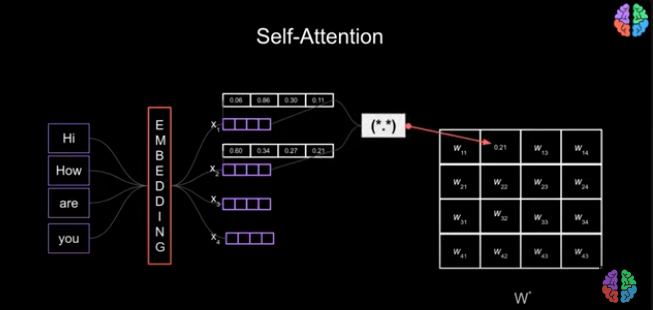
Here, we are trying to use self-attention to understand the relevance of each word in the word sequence: Hi, How are you. The words are passed through an embedding layer, which can be a Feedforward Neural Network (Chapter 21). This, in turn, converts the words into 4 arrays of vectors, given that numbers are what our computers understand. Each vector is created based on its position in the word sequence, so the vector for the word “Hi” knows its exact position in the sequence. As shown in the illustration, x1, x2, x3, and x4 all know their positions in relation to other words.
This is achieved using what is called Dot Production Notation. Multiply the weights and the vector arrays x1... xn to get W, as shown below, to get Y vectors. These Y vectors are “context-aware.”
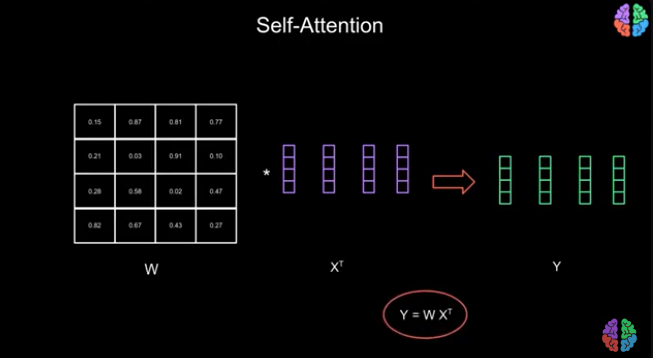
This is a very basic illustration of how self-attention works, but I believe you understand the concept.
Now, the Google researchers came up with their own type of self-attention, which they call Scaled Dot-Product Attention.
Scaled Dot-Product Attention
Scaled Dot-Product Attention is the core mechanism behind self-attention in transformer models. It determines how much relevance each token (word) should give to others in a sequence.
Formula:
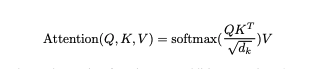
where:
Q (Query) – The current token trying to find relevant information.
K (Key) – The tokens that might be relevant.
V (Value) – The actual information to retrieve.
dk (Scaling factor) – The dimension of keys, used to prevent large values from causing unstable gradients. Simply means scaling down values.
softmax - Converts numbers into probability distribution, which simply means converts numbers to a range of 0-1
We know about dictionaries/objects/maps, right? If not, they are simply called key-value pairs. Where a key is used to retrieve a value. An example of a key-value pair of words, with the key being an English word and the value the French word:
{
“cat”: “chat”,
“dog”: “chien”,
}
Now, to access the French word, we need to pass in the English word as the key, so if we pass cat, we get chat. The Scaled Dot-Product Attention formula uses a similar key-value pair relationship with vectors this time, just like the x1…, xn vectors we had in our illustration of self-attention.
To make the Transformer more robust in parallel, the Google Research team added what they call Multi-Head Attention.
Multi-Head Attention
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. The image below shows the implementation of both Scaled Dot-Product Attention and Multi-Head Attention.
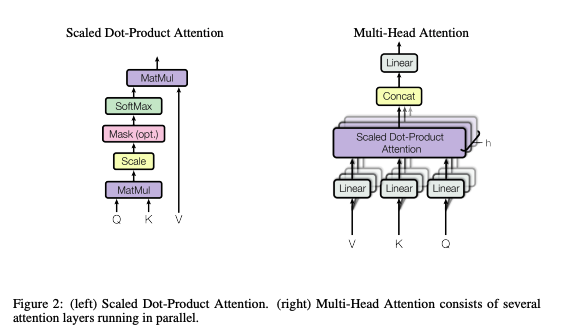
I know there are a lot of moving parts here; we’ll get to learn and understand them more as we continue learning. What the Google Researchers were able to achieve here is to create a model where operations can be run in parallel instead of the sequential way RNNs and CNNs run.
Here is the complete transformer architecture:
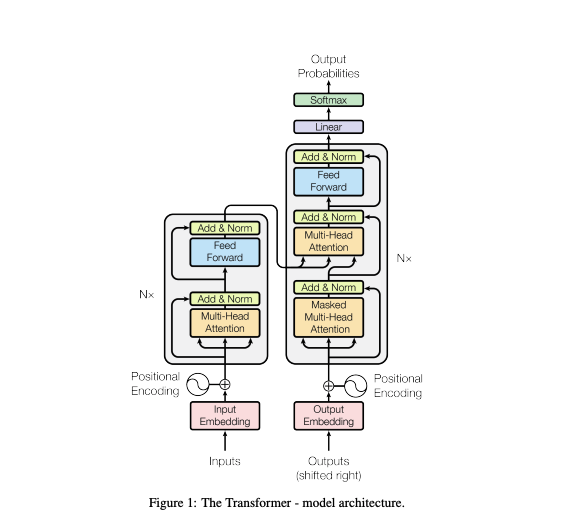
The transformer architecture is basically made up of multi-head attention layers stacked together. The encoder is by the left while the decoder is by the right, as shown in the figure above.
So why was this a breakthrough model architecture?
The total computational complexity per layer is better than RNN and CNN.
The amount of computation that can be parallelized, as measured by the minimum number of sequential operations required. This is very important, because now we can maximize the power of our computer systems for processing tasks very fast. We learned about this in our mid-series special 2, Why AI models prefer GPUs to CPUs. It’s a great read 🕶️ 🦾.
The path length between long-range dependencies in the network.
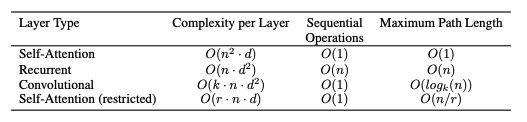
If you know about Big O notation, you’ll see here how self-attention in transformers performs better in paths per length.
Path length refers to the number of computational steps required for information to travel between two distant tokens in a sequence. This is crucial for capturing long-range dependencies, such as understanding relationships between words far apart in a sentence
Big O Notation is a mathematical way to describe the efficiency (time or space complexity) of an algorithm.
Here is an excerpt from the conclusion of the Google Brain and Research Teams on their paper, Attention Is All You Need.
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
Whew! That was a lot, even for me 😁. As we know, Transformers are used in a lot of AI technologies, including Large Language Models like GPT and Large Action Models.
Up next, we’ll learn about Large Language Models. 👽