Introduction To Large Language Models (LLMs)
AI Series - Chapter 31

I am a software engineer.
Hello 🤗,
We’ve come a long way in our AI series.
Let me start with a brief recap. We started from scratch with Supervised and Unsupervised Learning models, where we learned and built models like K-Nearest Neighbors, Naive Bayes, K-Means Clustering, and so on. We proceeded to learn Semi-Supervised and Reinforcement Learning. This led us to the breakthrough model, the Neural Network. We learned and built different types of Neural Networks, from Feedforward, Convolutional, Recurrent, and Generative Neural Networks. Neural Networks led us to Introduction to Transformers. We’ve built over 30 models and deployed 22 of those successfully 🦾.
We had awesome mid-series specials in between, where we discussed abstract ideas, concepts, and hypotheses like AI Hallucinations, The Void In Vibe Coding, Why AI Models Prefer GPUs to CPUs, and so on. We all loved those pieces 🫶.
Today, we’ve come almost full circle. We could have started this series with Large Language Models (LLMs) since they are hot and the ‘eureka’ moment of AI and Machine Learning. But we intentionally chose to learn from scratch, which is what differentiates the good from the great engineer.

It’s been a long intro, so let’s get right into it. 💨
I am almost certain that if you’re reading this, you’ve used a Large Language Model already. They’re everywhere. The term AI is virtually synonymous with LLMs now. We’ve used them in chat applications like ChatGPT, Grok, Meta AI, Perplexity, etc. They answer our questions with seemingly god-like knowledge, they serve as our therapist 🙂, they create new images, music, and videos from simple text prompts, it’s like magic.
To digress here a bit, we were also able to generate new images with our GAN models, generate new text (song lyrics in our case) using our RNNs, and so on with our Neural Network Models. They are just not close enough to what the LLMs are doing right now.
So what are Large Language Models?
Large Language Models
A Large Language Model (LLM) is a neural network (usually based on the Transformer architecture with large parameters) trained on huge datasets of text such as books, articles, websites, and code.
Its goal is to predict the next word (or token) in a sequence, but doing that well turns out to enable many powerful abilities. They are mostly generative AI, and with the huge amount of data they are trained on, they seem to just know everything, almost.
The Transformer model architecture is key to LLMs. We learned about Transformers in Chapters 25 and 26, respectively. Check them out to refresh your memory.
Now, what are the huge datasets and large parameters that make up the Large Language Model?

Huge Datasets
The huge datasets come from different domains, like the entire Twitter (X) conversations/messages over decades, Reddit, Facebook, the entire public repositories in Github, books, and even YouTube videos/Spotify songs are transcribed, amongst others. You can see these are huge datasets running into thousands of terrabytes. It is basically the entire information on the internet and even outside the internet.
Large Parameters
LLM parameters are the settings that control and optimize a large language model’s (LLM) output and behavior. Trainable parameters include weights and biases and are configured as a large language model (LLM) learns from its training dataset. We learned about weights and biases when learning about neural networks in Chapter 20, Introduction to Neural Network, you can refresh your memory. Then there are also Hyperparameters, which are external to the model, guiding its learning process, determining its structure, and shaping its output.
So when you hear something like LLaMA 70B, LLaMA 315B, or Falcon 40B. The figure attached is the number of parameters in billions! That means LLaMA 70B was trained using 70 billion parameters. To put that into perspective, when we were training our mood recognition model in Chapter 28, Code: Convolutional Neural Network, we maxed out at merely 128 parameters, that’s the filters we used (still based on the weights and biases), and it worked fairly well. Now you see why they are called Large Language Models.

There are several types of Large Language Models (also known as foundation models), but we’ll focus on 3 pivotal ones.
Bidirectional Encoder Representations from Transformers (BERT)
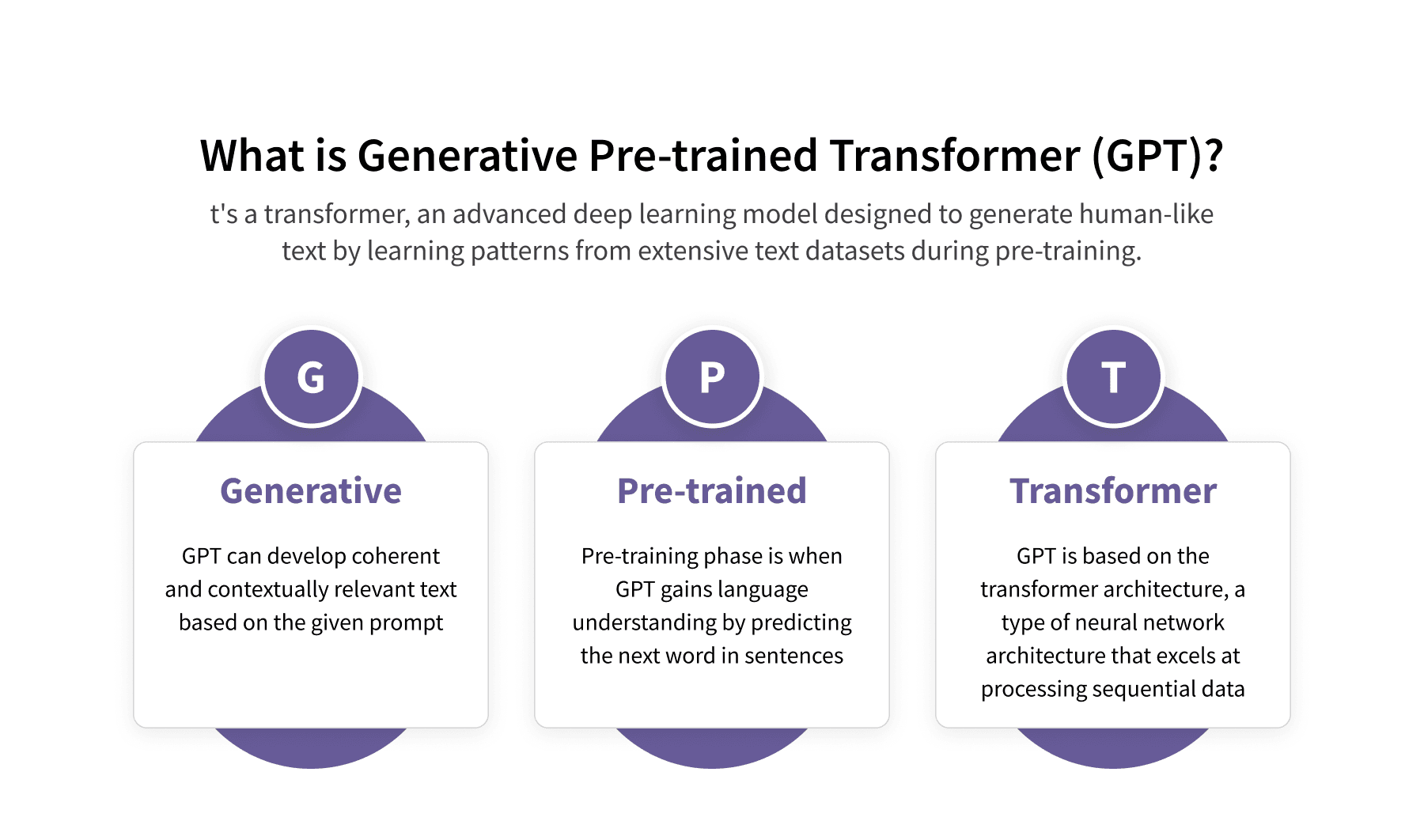
Generative Pre-Trained Transformers (GPT)
Large Language Model Meta AI (LLaMA)
This is just an introduction to LLMs. There is still a lot to learn about LLMs, and we’ll learn more and more with each type of LLM. Welcome to the big leagues! As you know already, WE’LL BUILD THE MODELS! 🦾
We’ll start with BERT in our next series chapter 👽
Enjoy your time 💭