Hands-on with Unsupervised Learning models
AI Series - Chapter 16

I am a software engineer.
Hello 🤗,
We'll continue where we left off and round up unsupervised learning in this chapter. We have extensively learned about unsupervised learning in the previous chapter, we learned about K-Means clustering and Principal Component Analysis (PCA) as well.
In this chapter, we'll practically build unsupervised learning models with K-Means clustering and PCA.
So let's get right into it already 🏃🏼.
Playground
We still have our playground, retzam-ai.vercel.app to help you play around with our trained models. 🎮
Hands-On
We'll use Python for the hands-on section, so you'll need to have a little bit of Python programming experience. If you are not too familiar with Python, still try, the comments are very explicit and detailed.
We'll use Google Co-laboratory as our code editor, it is easy to use and requires zero setup. Here is an article to get started.
Here is a link to our organization on GitHub, github.com/retzam-ai, you can find the code for all the models and projects we work on. We are excited to see you contribute to our project repositories.
For this demo project, we used a dataset on seeds. The examined seeds group comprised kernels belonging to three different varieties of wheat: Kama, Rosa, and Canadian, 70 elements each, randomly selected for the experiment.
You can get the dataset here.
We'll train a model to help us cluster seeds based on their features, which we can then use to determine which kernel group it belongs to.
For the complete code for this tutorial check this pdf here.
Data Preprocessing
Create a new Colab notebook.
Download seeds dataset here.
Import the dataset to the project folder.
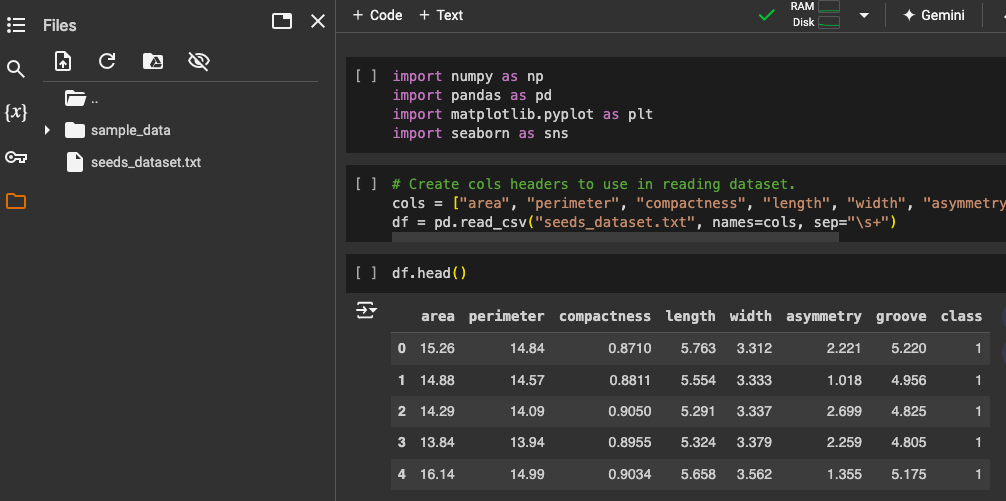
Import the dataset using pandas.
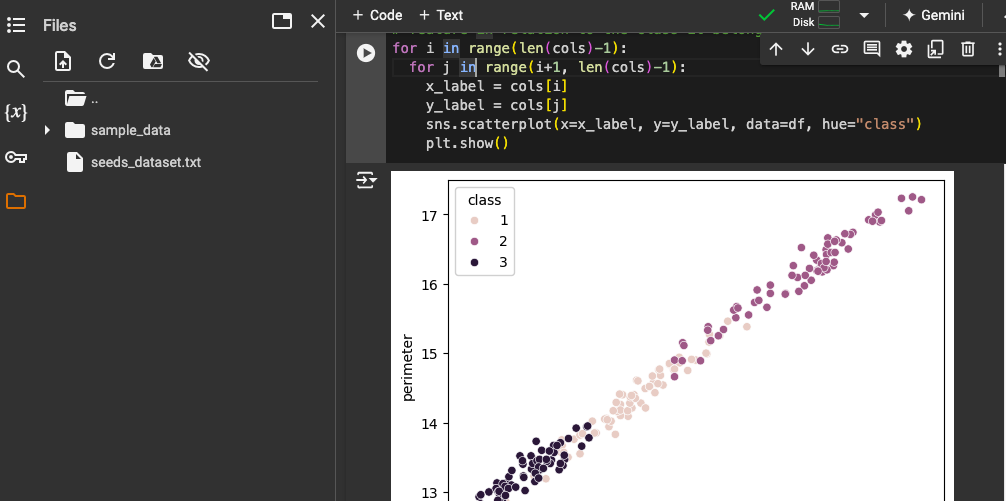
Create a scatter plot of all features to the class. This would help us see the different patterns for each feature in relation to the class it belongs to.
In the screenshot below we can see each feature position and each class(group) has a different color to mark the 3 groups.
Train K-Means Model
We'll go ahead to train our K-Means model by importing the library from SK-Learn cluster.
We then use 2 features, the perimeter and asymmetry features of the dataset to create our cluster.
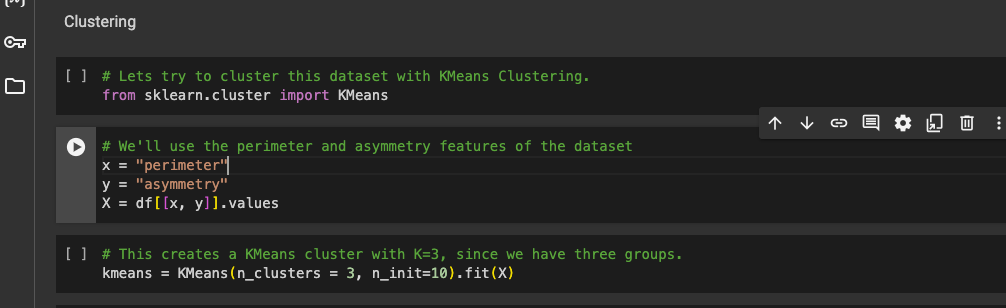
Then we train our model (by using the fit method).
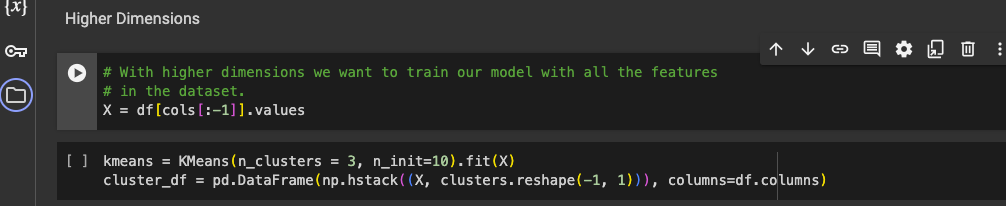
Train Higher Dimensions K-Means Model
With higher dimensions we will use all the features in our dataset instead of 2 we used in the model above to train our model.
Reduce Dimensions with Principal Component Analysis (PCA)
I believe we remember PCA and dimension reduction right? Remember we use PCA to reduce dimensions also known as reducing features to help us make better predictions.
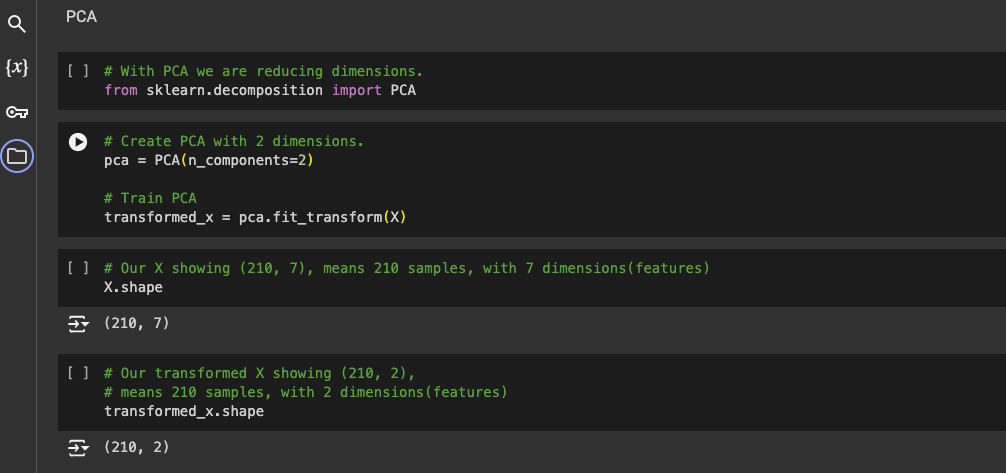
The screenshot below shows us using PCA from SK-Learn decomposition library to transform our dataset. We want to create a dataset with 2 dimensions.
We can also see the shape
Before reduction - showing 210 rows and 7 dimensions(features)
After reduction - showing 210 rows and 2 dimensions
This means we have successfully reduced our dimensions from 7 to 2 dimensions using PCA 🤖
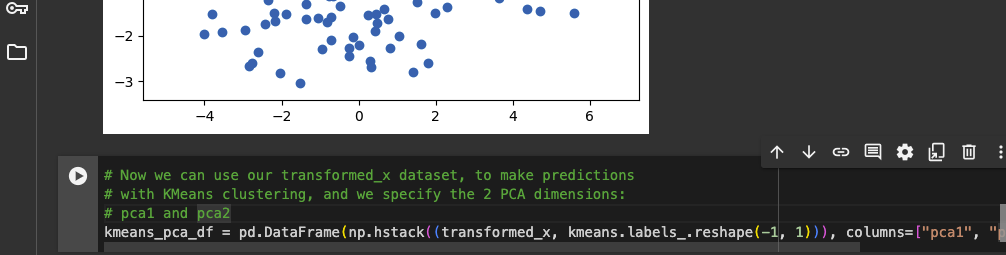
Train K-Means model with dataset transformed with PCA
We can use the transformed PCA dataset to train our K-Means model.
You can download the jupyter notebook here, it shows the complete code base.
In conclusion, we have trained a K-Means model to help us cluster seeds into 3 groups, we transformed a dataset from 7 to one with 2 dimensions(features) we then lastly used the transformed dataset to train another K-Means model. The notebook visualize and compare the predictions of the models, so do well to work with the notebook.
The end.
Yay🎉✅! We just concluded unsupervised learning ✅!

Remember it's all about practice, practice, practice, so keep on trying new projects with new datasets. We've made tremendous progress in our AI and ML journey so don't slip up, keep on 🦾.
Up next we'll learn about Semi-Supervised Learning, it'll be interesting and enlightening as always.
Cheers! 👽